AB 08 — GUI oder Shell?
Anfänger finden sich im GUI durch die grafischen Darstellungen viel schneller und leichter zurecht. Außerdem sind sie dieses Arbeiten von Windows gewohnt.
Kennt man jedoch die benötigten Befehle erst einmal, so führen diese meist schneller und präziser zum Ziel. Zudem haben die Befehle sich in all der Zeit kaum verändert. Skripte und Dokumentation sind mit Shell-Befehlen sehr einfach zu erstellen. Linux-Administratoren beachten die ständig wechselnden GUIs deshalb kaum. Langfristig führt also kein Weg an den Shell-Befehlen vorbei. Deshalb sollte man hauptsächlich mit diesen arbeiten, nachdem das Verständnis mit Hilfe des GUI und dessen Hilfs-Programmen erreicht wurde.
| GUI | Shell-Befehle |
|---|---|
| erlaubt ungeübten Benutzern schneller zum Ziel zu kommen vermittelt besser das Verständnis der ausgeführten Aktionen | leichter zu dokumentieren versions- und distributions-unabhängig |
| das Dokumentieren der ausgeführten Schritte ist aufwendig und erfordert meist Screenshots. Diese sind auf die aktuelle Version und Distribution begrenzt | man muss die benötigten Befehle mit Optionen allesamt kennen |
Kapitel – Programme und Prozesse
« Wenn Du im Recht bist kannst du Dir es leisten, due Ruhe zu bewahrend, und wenn Du im Unrecht bist, kannst du Dir nicht leisten sie zu verlieren. »
- Mahatma Gandhi
Im vorangegangenen Kapitel haben wir uns im Wesentlichen mit dem Bootvorgang beschäftigt. Es ist jedoch interessanter, was passiert, wenn das System einmal läuft. Dazu werden wir uns im Folgenden mit Prozessen unter Linux befassen.
- Was ist ein Prozess?
Ein Prozess ist die laufende Instanz eines Programms/Befehls und wird durch einen numerischen Schlüssel, den Process Identifier (kurz: PID), repräsentiert. Der PID ist einmalig und hat seinen eigenen, privaten Arbeitsbereich im Speicher (RAM), der vor dem Zugriff durch andere Programme geschützt ist - er ändert sich während der Laufzeit nicht.
Bei jedem Start eines Programmes/Befehls wird also ein oder sogar mehrere Prozesse gestartet. So erzeugt z.B. Firefox für jeden Tab einen eigenen Prozess zwecks Stabilität.
Jeder Prozess benötigt für seine Ausführung sowohl Arbeitsspeicher (RAM) als auch Prozessorleistung (CPU).
Wenn von Prozessen die Rede ist, meint man in der Ausführung befindliche Programme. Jedoch bestehen zwischen Programmen und Prozessoren grundlegende Unterschiede, die jedem Linux-Benutzer klar sein sollten. Ein Programm ist prinzipiell einfach nur eine Datei die in binärer Form vorliegt und einem maschinenlesbaren Code enthält. Dieser Code beschreibt Anweisungen zur Steuerung des Systems. Erst wenn man das Programm startet, wird es schließlich zum Prozess.
Es gibt verschiedene Dateiformate, in denen so ein Programm vorliegen kann. Linux verwendet standardmäßig das ELF-Format, kann aber auch mit älteren a.out-Dateien umgehen. An dieser Stelle reicht es, wenn Sie wissen, dass es solche Formate für Binärdateien gibt. Vielleicht ist es noch interessant zu erwähnen, dass in ELF-Dateien zur Identifizierung als allererstes Byte 0x7f, gefolgt von den drei Buchstaben ELF, gespeichert wird. Der Rest dürfte aus einem Gewirr von Sonderzeichen bestehen und unlesbar sein. Aber es handelt sich ja auch schließlich um ein Programm und nicht um einen Text.
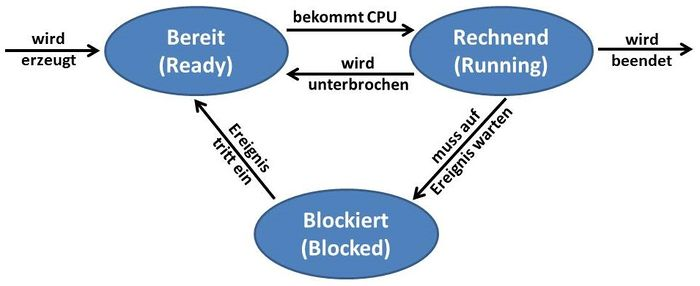
Zustände
Abschnitt betitelt „Zustände“Jeder Prozess kann während seiner Ausführung über mehrere Zustände verfügen je nachdem in welcher Phase der Ausführung er sich befindet.
Ein Prozessor(kern) kann immer nur einen Prozess gleichzeitig verarbeiten. Bei den ersten Computern wurden daher die Programme immer nacheinander als Ganzes verarbeitet, es konnte immer nur ein Programm zur gleichen Zeit ablaufen. Es konnten auch nicht mehrere Benutzer einen Computer gleichzeitig unabhängig voneinander verwenden. Daher wurde die Möglichkeit geschaffen, Prozesse nur teilweise auszuführen, zu unterbrechen und später wieder aufzusetzen und fortzuführen. Durch schnelles Abwechseln können mehrere Prozesse quasi-gleichzeitig ausgeführt werden. Das Prozessmodell beschreibt die drei wesentlichen Prozesszustände, die je nach Ausgestaltung um weitere ergänzt werden können:
-
BEREIT: Der Prozess besitzt alle benötigten Betriebsmittel (Ressourcen) (bis auf den Prozessor(kern)) und wartet auf seine weitere Ausführung.
-
LAUFEND: Der Prozess ist aktuell einem Prozessor(kern) zugeordnet und läuft auf diesem ab.
-
BLOCKIERT: Der Prozess wurde unterbrochen und wartet auf eine nicht-Prozessorkern-Ressource. Wenn die Zuteilung erfolgt ist, wird er zunächst wieder in den Zustand BEREIT versetzt.
Die Prozesse werden vom „Prozess-Scheduler“ des Betriebssystems verwaltet. Er führt entsprechende Listen und versucht, wartenden Prozessen möglichst schnell die benötigten Ressourcen zuzuteilen, teilt ausführungsbereiten Prozessen Zeitscheiben zu und startet sie.
Ein laufender Prozess kann durch drei Ereignisse unterbrochen werden:
-
Ablauf seiner Zeitscheibe, meist als Ablauf eines Hardware-Timers, der dann einen Hardware-Interrupt auslöst.
-
Hardware-Interrupt; ein (unvorhergesehenes) Ereignis eines Geräts, zum Beispiel ein Tastendruck auf der Tastatur.
-
eigener Wunsch; der Prozess benötigt eine Dienstleistung des Betriebssystems oder hat seine Arbeit beendet.
Der dann wieder aktive Prozess-Scheduler regelt das weitere Vorgehen.
Ausführen von Prozessen
Abschnitt betitelt „Ausführen von Prozessen“Single Tasking
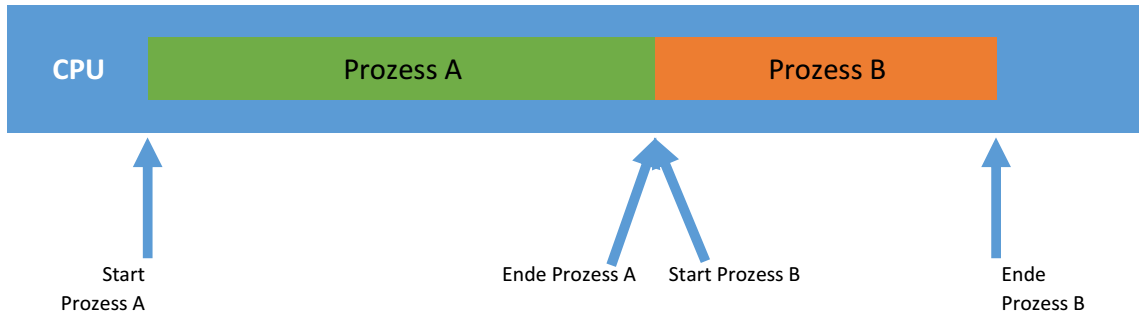
Abschnitt betitelt „Single Tasking“Single Tasking beschreibt die Verarbeitung eines einzelnen Programmes durch die CPU. D.h. auf dieser Maschine können niemals mehrere Programme/Befehle gleichzeitig verarbeitet werden. Beispiele hierfür:
-
Die ersten Computer
-
Haushaltsgeräte (Mikrowelle, Spühlmaschine, …)
-
Rechenmaschine
Alle diese Geräte haben nur eine einzige Aufgabe und müssen nur dieses Ausführen können.
Multitasking
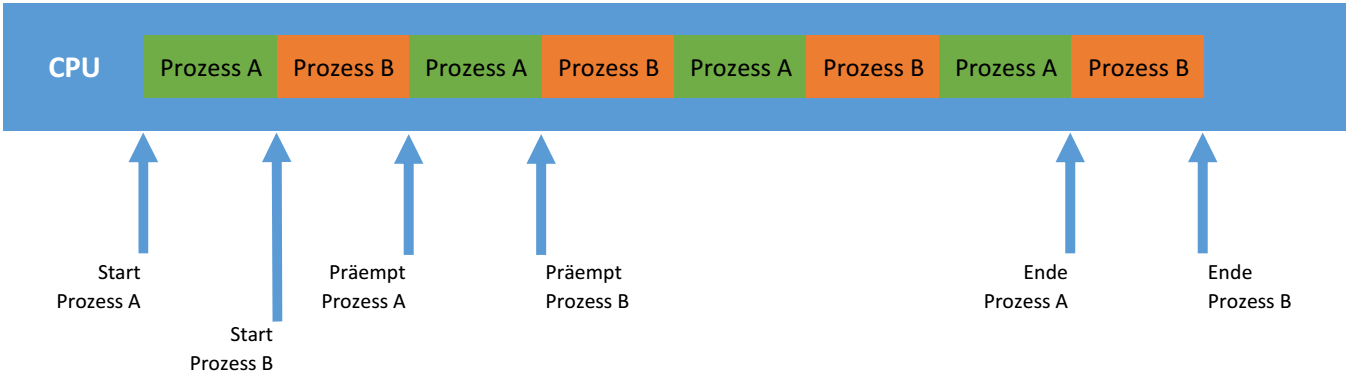
Abschnitt betitelt „Multitasking“Der Begriff Multitasking bzw. Mehrprozessbetrieb bezeichnet die Fähigkeit eines Betriebssystems, mehrere Aufgaben (Tasks) (quasi-)nebenläufig auszuführen. Die verschiedenen Prozesse werden in so kurzen Abständen immer abwechselnd aktiviert, dass der Eindruck der Gleichzeitigkeit entsteht. Multitasking ist somit ein Synonym für Zeit-Multiplexverfahren.
Der Grundgedanke hinter Multitasking ist der, dass in einem durchschnittlichen Rechner der überwiegende Teil der Rechenzeit nicht genutzt werden kann, weil häufig auf verhältnismäßig langsame, externe Ereignisse gewartet werden muss (beispielsweise auf den nächsten Tastendruck des Benutzers). Würde nur ein Prozess laufen (zum Beispiel die wartende Textverarbeitung), so ginge diese Wartezeit komplett ungenutzt verloren (siehe „aktives Warten“). Durch Multitasking kann jedoch die Wartezeit eines Prozesses von anderen Prozessen genutzt werden.
Ist ein Rechner bzw. seine Rechenzeit demgegenüber größtenteils ausgelastet, beispielsweise durch einzelne rechenintensive Prozesse, so können dennoch mehrere Benutzer oder Prozesse anteilige Rechenzeit erhalten, anstatt auf das Ende eines anderen Prozesses warten zu müssen. Dies kommt insbesondere auch der Interaktivität zugute.
Besitzt ein PC gar mehr als eine CPU oder mehrere Prozessorkerne, können bedingt von der Anzahl der Kerne mehrere Prozesse zur gleichen Zeit ausgeführt werden. Dieses Verhalten wird auch als „Multiprocessing“ bezeichnet.
Kooperatives Multitasking
Abschnitt betitelt „Kooperatives Multitasking“Beim kooperativen Multitasking gibt der Scheduler die Kontrolle komplett an den Prozess ab. Als Konsequenz davon ist das Betriebssystem darauf angewiesen, dass der Prozess seinerseits die Kontrolle “freiwillig” wieder zurückgibt. Geschieht das nicht, wird der Scheduler nicht wieder aufgerufen und damit auch kein anderer Prozess mehr ausgeführt - das System “hängt”. Bekannte Beispiele sind Windows 3.x und MacOS vor Version 10.
Dennoch ist kooperatives Multitasking keineswegs überholt oder schlecht. Gerade im Bereich der Mikrocontroller und Echtzeitanwendungen gibt es viele gute Argumente dafür: Kooperatives Multitasking ist deterministischer, also besser zeitlich und logisch vorhersagbar. Es ist besser simulierbar, d. h. für ein gegebenes System ist leichter nachweisbar, dass es funktioniert. Da es sich um geschlossene Systeme handelt, tritt das Problem, dass “irgendein” Prozess das System anhält, nicht auf. Es laufen ja im Gegensatz zum PC nicht “irgendwelche” Prozesse, sondern nur die, deren Korrektheit (im Idealfall) verifiziert und validiert wurde.
Präemptives Multitasking
Abschnitt betitelt „Präemptives Multitasking“Basis der heutzutage standardmäßig angewendeten Methode ist das präemptive Multitasking. Die Abarbeitung der einzelnen Prozesse wird ebenfalls gesteuert durch den Scheduler, ein Bestandteil des Betriebssystemkerns. Jeder Prozess wird nach einer bestimmten Abarbeitungszeit unterbrochen. Dabei spricht man auch von so genannten Zeitschlitzen (bzw. Zeitscheiben, engl. time slices/slots). Dann „schläft“ der Prozess (ist inaktiv) und andere Prozesse werden bearbeitet. Erhält er wieder eine Prozessorzuteilung, so setzt er seine Arbeit fort (ist aktiv).
Prioritäten
Abschnitt betitelt „Prioritäten“Beim Multitasking lässt sich jedem Prozess eine Priorität vergeben. Diese Priorität wird vom Scheduler berücksichtigt und sorgt dafür, dass besonders priorisierte Prozesse vorrangig von der CPU verarbeitet werden. Prozesse mit einer schlechteren Priorität müssen dann länger auf die Zuweisung der CPU warten.
Die Prioritäten variieren von sehr niedrig bis zu sehr hoch oder sogar Echtzeit (real time). Dabei erhält ein Prozess die gesamte CPU-Leistung wobei wir wieder beim kooperativen Multitasking wären.
1.1 Das Starten eines Programms
Möchte man eine Binärdatei ausführen, wird der Programmcode in den Userspace geladen. Der für das Programm reservierte Speicher im Userspace besteht aus verschiedenen Bereichen. Im sogenannten Code-Segment sind die Prozessoranweisungen hinterlegt, im Daten-Segment werden die eigentlichen Informationen gespeichert, und im Heap-Segment wird dynamisch reservierter Speicher untergebracht.
Ein Prozess ist also ein Programm, das soeben ausgeführt wird, Linux ordnet dabei jedem Prozess eine eindeutige Identifikationsnummer zu, die sogenannte Prozess-ID (PID). Zu einem Prozess gehören aber nicht nur die PID und das Programm bzw. der Programmteil den er repräsentiert. Vielmehr besitzt ein Prozess noch weitere Eigenschaften, beispielsweise eine Umgebung mit Shell Variablen, einen Rechtekontext sowie ein Arbeitsverzeichnis.
- Eltern- und Kind-Prozesse
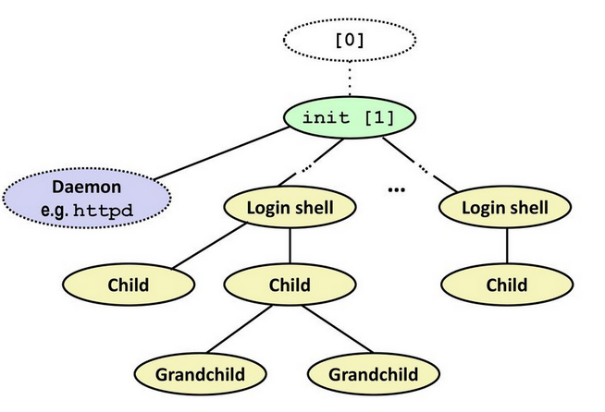
Die Überschrift suggeriert ein harmonisches Familienbild: Mama- und Papa-Prozess kümmern sich liebevoll um den kleines Klaus-Herbert, der auch mal ein großer Prozess werden will. Leider müssen wir Sie aus dieser perfekten, fast schon christlich-konservativen Familienidylle wieder herausreißen: Es soll hier nur um eine Einführung in die hierarchische Prozessverwaltung von Linux gehen.
Eine solche Prozessverwaltung bedeutet nichts anders, als dass Prozesse nicht einfach so neu entstehen, sondern einen Vater haben, von dem sie erstellt wurden. Den Vorgang des Erzeugens nennt man forking, zu Deutsch etwa „verzweigen“, da in der Prozesshierarchie ein neuer Zweig entsteht. Dabei erbt der Kind-Prozess alle wichtigen Eigenschaften wir die Prozessumgebung vom Vater. Der Urvater alles Prozesse ist dabei – wie Sie es wahrscheinlich Wissen der init-Prozess, der beim Booten explizit vom Kernel gestartet wird.
Beim Forking erstellt dem Kernel einen neuen Eintrag in der Prozesstabelle (auf die wir gleich noch zu sprechen kommen), und er wird dem Prozess später Rechenzeit zuteilen, damit das „Programm“ beziehungsweise der Programmcode ausgeführt werden kann.
Durch die vom Eltern-Prozess teilweise ererbte Prozessumgebung bekommt der Prozess alle wichtigen Informationen über sich und das System, damit er einwandfrei seine Arbeit verrichten kann.
- Das Kernel und seine Prozesse
Beschäftigen wir uns aber einmal kurz mit einer eher technischen Seite der Prozesse, indem wir über Prozesse im Zusammenhang mit dem Kernel reden. Damit wollen wir Ihnen wichtige Grundlagen vermitteln, sodass Sie das System verstehen.
Aus dem Blickwinkel des Kernels durchläuft ein Prozess drei primäre Lebensstadien: Er wird erzeugt, verarbeitet und beendet. Beim Start wird unter anderem jedem Prozess Speicher zugeteilt. Dies erfolgt über das kernelinterne Memory-Management-System.
Das Linux ein Multitasking-Betriebssystem ist und alle Prozesse „gleichzeitig“ ablaufen sollen, wird jedem Prozess eine kurze Zeitschreibe zugeteilt. In dieser Zeit kann der Prozess seine Arbeit verrichten. Alle Prozesse werden vom Kernel dabei in einer Art Warteschlange verwaltet.
Diese Warteschlange stellt anhand bestimmter ausgefeilter Algorithmen sicher, dass beispielsweise kein Prozess vergessen wird und trotzdem allen Prozessen entsprechend ihrer Priorität mehr oder weniger zugeteilt wird.
- Die Prozesstabelle
Das Herz der Kernel-Prozessverwaltung ist die Prozesstabelle. Diese Tabelle ist aber eigentlich keine richtige Tabelle, da eine solche zu statisch und damit einfach unhandlich wäre. Stattdessen werden alle für einen Prozess relevanten Informationen in einer speziellen Struktur gespeichert. In dieser Struktur ist dabei ein Verweis auf den jeweils vorherigen und nächsten Prozess in der Prozesstabelle gespeichert. Diese Art der Speicherung nennt man auch eine doppelte verkettete Liste.
Die Prozesstabelle ist also eigentlich eine Liste und keine Tabelle. Aber wie dem auch sei, jedenfalls speichert die Struktur jedes einzelnen Prozesses noch zusätzliche Informationen, wir beispielsweise das aktuelle Stadium, die Prozesspriorität, sein Terminal und das Arbeitsverzeichnis, die empfangenen Signale und schließlich Dateideskriptoren, wie etwa die für Sockets und einige weitere Daten.
Zu diesen weiteren Daten gehören natürlich auch Verweise auf den Vater und beispielsweise das jüngste Kind. Mit diesen Informationen wird also gleichzeitig auch noch die Prozesshierarchie verwaltet.
- Der Prozessstatus
Der Status eines Prozesses beschreibt seinen aktuellen Zustand. Dieser Wert wird natürlich auch von der Prozesstabelle vorgehalten.
-
laufend
-
In diesem Stadium befindet sich der Prozess in der Verarbeitung und nutzt demnach die ihm zugeteilte Rechenzeit.
-
schlafend
-
In diesem Stadium „schläft“ der Prozess und wird erst nach Beendigung der Schlafphase bzw. beim Eintreffen eines Signals oder der Zugriffsverfügbarkeit eines Deskriptors wieder „wach“, d.h. aktiv weiterverarbeitet. Ein Beispiel wäre der stockende Empfang von Netzwerkdaten. Dabei würde das Kernel den Prozess schlafen schicken, solange der Empfangspuffer keine Mindestmarke erreicht hat.
-
gestoppt
-
Die Ausführung des Prozesses wurde abgebrochen und muss entweder manuell vom Administrator oder vom Kernel fortgesetzt werden. Wir beschäftigen uns mit dem Stoppen und Fortsetzen eines Prozesses noch genauer.
-
Zombie
-
Unter UNIX müssen Eltern-Prozesse ihre Kind-Prozesse verwalten, das heißt, sie müssen nach einem Start auch auf die Beendigung warten. Ist die Beendigung eines Kind-Prozesses eingetreten, ohne dass der Eltern-Prozess auf dessen Beendigung wartet, so wird der Prozess nicht aus dem Speicher gelöscht. In diesem Stadium spricht man von Zombie-Prozessen. Sie existieren also, obwohl sie schon „tot“ sind.
-
Prozess-Environment
Wir sind bereits sehr detailliert auf die Prozesstabelle eingegangen. Wer an weiteren Details interessiert ist, der möge sich ein die Datei sched.h aus dem include-Verzeichnis der Linux-Sourcen anschauen. Denn anstatt uns weiter mit Implementierungsdetails zu quälen, möchten wir uns jetzt lieber mit der Prozessthematik aus Sicht des Anwenders und Administrators befassen. Die Merkmale eines Prozesses sind folgende:
-
PID
-
Die Prozessnummer (PID) wird jedem Prozess bei seiner Erstellung vom Kernel gegeben. Sie ist nicht nur für das Kernel wichtig, sondern auch für den Eltern-Prozess, um seine Kind-Prozesse zu verwalten. Die Prozessnummer ist absolut eindeutig und wird somit als wichtigste Identifikation des Prozesses gebraucht.
-
PPID
-
Die PID des Eltern-Prozesses wiederum dient der Zuordnung eines Kind-Prozesses zu seinen „Vorfahren“. Manchmal ist diese Zuordnung für Programmierer wichtig, der Anwender kommt damit jedoch eher selten in Kontakt.
-
UID und GUID
-
Die Nummer des Benutzers und seiner Gruppe ist besonders wichtig, um die Zugriffsrechte des Prozesses zu ermitteln. Wenn ein Benutzer aus einer Shell einen Editor startet, um eine Datei zu bearbeiten, erbt der Editor die UID und GID des Benutzers von der Shell. Wenn der Editor nun die Datei eröffnen will, können diese Informationen dazu herangezogen werden, um die Berechtigungen des Benutzers zu prüfen.
-
Arbeitsverzeichnis
-
Alle Dateinamen, die nicht mit einem Slash, also mit / anfangen, werden relative Pfadnamen genannt. Diese Pfadangaben beziehen sich dann auf das aktuelle Arbeitsverzeichnis, das der Prozess natürlich auch von seinem Vater erbt.
-
Bei der Arbeit mit Prozessen steht oft die Frage im Vordergrund, ob ein Prozess bzw. ein Programm ihre direkte Aufmerksamkeit erfordert oder ob es still im Hintergrund seine Arbeit verrichten kann.
-
Eine spezielle Art von Prozessen sind die sogenannten Dämonprozesse. Sie arbeiten im Hintergrund und werden vorwiegend für Aufgaben genutzt, für die es keiner direkten Kontrolle bedarf. Das sind Serverdienste, wir beispielsweise Webserver oder Mailserver.
-
Dämonprozesse und Shell-Hintergrundprozesse
Dummeweise werden Dämonprozesse oftmals mit den Hintergrundprozessen der Shell verwechselt. Wie wir oben jedoch erläutert haben, sind Dämonprozesse eigene Sessionführer und unabhängig von einer Shell.
Solche Dämonprozesse werden normalerweise während des Bootens gestartet und erst beim Shutdown des Systems beendet, indem der Kernel TERMINATE- bzw. KILL-Signal an den Prozess sendet.
- Prozessadministration
Im letzten Abschnitt dieses Kapitels beschäftigen wir uns mit der Administration von Prozessen. Ein sehr wichtiges administratives Programm (nämlich kill) kennen Sie bereits. Die folgenden Programme dienen primär dazu, sich einen Überblick über die laufenden Prozesse zu verschaffen.
- Prozesspriorität
Bei der Berechnung der Prozesspriorität spielt vor allem der sogenannte Nice-Wert eines Prozesses eine wichtige Rolle. Je nachdem, wie hoch (oder niedrig) dieser Nice-Wert ist, desto niedriger bzw. höher ist die Wahrscheinlichkeit, dass ein Prozess mit mehr CPU-Zeit beglückt.
| Nur der Administrator darf die Nice-Werte eines Prozesses erhöhen. Den normalen Benutzern ist es nur erlaubt, die Prozesspriorität herabzusetzen, was beispielsweise bei längeren Dateisuchen Sinn macht. |
|---|
- pstree
Das Kommando pstree (process tree) gibt einen Prozessbaum aus. Dies ist eine sehr sinnvolle Funktion, um sich einen Überblickt über das Verhalten einiger Programme und deren Kind-Prozesse zu verschaffen. Darüber hinaus eignet es sich hervorragend, um Linux-Prozesse und ihre Hierarchie kennenzulernen.
Was ist ein hierarchischer Prozessbaum? Die Hierarchie der Prozesse kennen Sie bereits. pstree visualisiert im Prinzip diese virtuelle Ordnung in einem ASCII-Baum – jeder Zweig des Baumes stammt von einem Vater-Prozess ab.
Prozessverwaltung in Linux
Abschnitt betitelt „Prozessverwaltung in Linux“Linux bietet vielerlei Möglichkeiten Prozesse zu verwalten. Zum einen lassen diese sich in jeder grafischen Oberfläche mit einem Programm (Process Manager, Activity Monitor, …) beobachten und steuern. Daneben bietet auch die bash eine Vielzahl an Befehlen um Prozesse mittels der Kommandozeile zu steuern:
| ps | zeigt alle momentan aktiven Prozesse an samt Zusatzinformationen (ps -aux) |
|---|---|
| pstree | zeigt alle Prozessbäume an, hier sieht man welche Prozesse von welchen Überprozessen gestartet wurden |
| top | quasi Task Manager in der Shell, zeigt Ressourcenverbrauch in Echtzeit an |
| htop | grafisch besseres top |
| kill | Sendet ein „Beenden“- Signal an einen konkreten Prozess durch Angabe seiner einer PID |
| killall | beendet jeden Prozess eines gegebenen Programmes/Befehls |
| nice | wird zum Setzen der Priorität in der Shell verwendet |
| renice | Ändern der Priorität eines Prozesses während seiner Ausführung |
| & | zum Starten eines Befehls im Hintergrund z.B. firefox & |